class: center, middle, nonum
# Tipos e Operações Primitivas
.center[]
### Programação I, Computação@UFCG
©2023 Dalton Serey, UFCG
---
## Tipos de dados
- Aplicações modernas de computadores manipulam uma
enorme quantidade de .green[tipos de dados] de diversas
complexidades.
- Hoje manipulamos documentos textuais,
imagens fotográficas, áudio e vídeo, contatos e redes sociais,
dados científicos, modelos de engenharia, etc, etc.
--
> Contudo, computadores e LPs .red[**não são capazes de**]
> .red[**representar e processar esses dados de forma nativa**],
> direta.
--
>
> Então... que tipos de dados computadores e LPs podem representar
> diretamente?
---
class: greenback center middle
# Tipos de dados no Hardware e no Sistema Operacional
---
# O Bit
No nível mais básico do hardware, computadores armazenam um único
tipo ou forma de dado: o .bgreen[bit] (aglutinação de
.bgreen[BI]nary digi.bgreen[T]). Bits permitem representar
dados binários:
 - os dígitos 0 e 1
- verdadeiro e falso
- ligado e desligado
- sim e não
Bits podem ser representados de variadas formas físicas (com ou
sem corrente, com ou sem nível de tensão, magnetizado de uma
forma ou de outra, etc). O bit é conveniente pela simplicidade e
confiabilidade com que pode ser representado e manipulado.
---
# O Byte
- os dígitos 0 e 1
- verdadeiro e falso
- ligado e desligado
- sim e não
Bits podem ser representados de variadas formas físicas (com ou
sem corrente, com ou sem nível de tensão, magnetizado de uma
forma ou de outra, etc). O bit é conveniente pela simplicidade e
confiabilidade com que pode ser representado e manipulado.
---
# O Byte
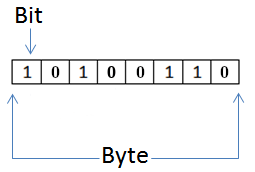 Um .bgreen[byte] é uma sequência de 8 bits tratados
como uma unidade indivisível. Permite representar 28
valores:
- números de 0 a 255
- ou com sinal, de -128 a 127
Na maioria absoluta das arquiteturas de hardwares modernas, _o
byte é a unidade mínima de representação e movimentação de
dados_.
Cada posição de memória de computadores modernos e de outros
dispositivos armazena um _byte_. Além disso, o byte é também a
unidade de dado da comunicação entre dispositivos, computadores e
até processos. É, por exemplo, a unidade de comunicação
de toda a Internet.
---
class: greenbar
# Representação de bytes
Bytes são sequências de 8 bits. Na prática, contudo, costumamos
representá-los como inteiros entre 0 e 255. Em particular,
representados em hexadecimal (quarta coluna abaixo).
.yscroll[```
00000000 0 0000.0000 00
00000001 1 0000.0001 01
00000010 2 0000.0010 02
...
00001101 13 0000.1101 0d
00001110 14 0000.1110 0e
00001111 15 0000.1111 0f
00010000 16 0001.0000 10
00010001 17 0001.0001 11
...
11111100 252 1111.1100 fc
11111101 253 1111.1101 fd
11111110 254 1111.1110 fe
11111111 255 1111.1111 ff
```
]
Tabela completa de bytes
---
class: redbar
# Há Bytes que não têm 8 bits
Embora hoje o byte de 8 bits seja o padrão de fato, isso
nem sempre foi verdade. Já houve (e até ainda há, em alguns
nichos bem pequenos) computadores com bytes de 4, 7
e 9 bits, por exemplo.
> Quando o termo byte pode ser ambíguo, é comum que se use o
> termo _octeto_. O termo é especialmente no caso de tecnologias
> de redes, em que o padrão é o uso de _octetos_ (unidades de 8
> bits).
---
# Caracteres e a Tabela Ascii
Um .bgreen[byte] é uma sequência de 8 bits tratados
como uma unidade indivisível. Permite representar 28
valores:
- números de 0 a 255
- ou com sinal, de -128 a 127
Na maioria absoluta das arquiteturas de hardwares modernas, _o
byte é a unidade mínima de representação e movimentação de
dados_.
Cada posição de memória de computadores modernos e de outros
dispositivos armazena um _byte_. Além disso, o byte é também a
unidade de dado da comunicação entre dispositivos, computadores e
até processos. É, por exemplo, a unidade de comunicação
de toda a Internet.
---
class: greenbar
# Representação de bytes
Bytes são sequências de 8 bits. Na prática, contudo, costumamos
representá-los como inteiros entre 0 e 255. Em particular,
representados em hexadecimal (quarta coluna abaixo).
.yscroll[```
00000000 0 0000.0000 00
00000001 1 0000.0001 01
00000010 2 0000.0010 02
...
00001101 13 0000.1101 0d
00001110 14 0000.1110 0e
00001111 15 0000.1111 0f
00010000 16 0001.0000 10
00010001 17 0001.0001 11
...
11111100 252 1111.1100 fc
11111101 253 1111.1101 fd
11111110 254 1111.1110 fe
11111111 255 1111.1111 ff
```
]
Tabela completa de bytes
---
class: redbar
# Há Bytes que não têm 8 bits
Embora hoje o byte de 8 bits seja o padrão de fato, isso
nem sempre foi verdade. Já houve (e até ainda há, em alguns
nichos bem pequenos) computadores com bytes de 4, 7
e 9 bits, por exemplo.
> Quando o termo byte pode ser ambíguo, é comum que se use o
> termo _octeto_. O termo é especialmente no caso de tecnologias
> de redes, em que o padrão é o uso de _octetos_ (unidades de 8
> bits).
---
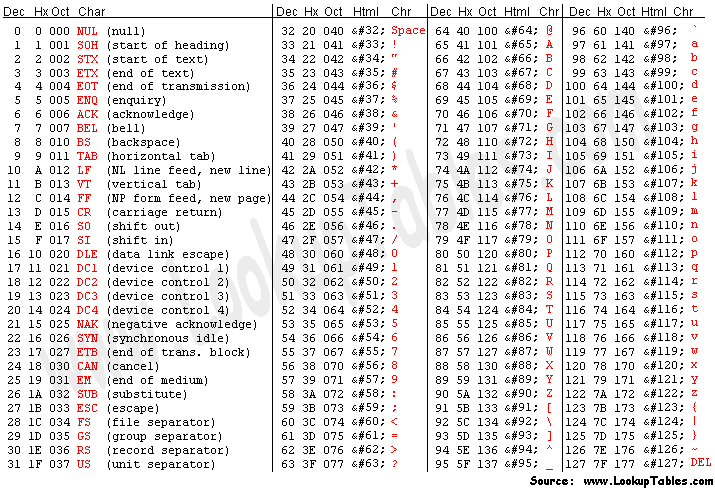
# Caracteres e a Tabela Ascii
 A tabela ASCII é um dos
_encodings_
mais antigos ainda em uso na
atualidade. A forma original usa apenas 7 bits e tem, por isso,
apenas 128 caracteres e não incluia caracteres acentuados, por
exemplo. Hoje, embora se use Unicode, os primeiros 128 códigos
são idênticos à tabela ASCII.
Diversas extensões foram criadas, usando 8 bits, para ajustá-la
ao tamanho do byte e para aacomodar mais 128 caracteres. Uma das
mais usadas é a conhecida Latin-1 ou ISO 8859-1 (que era adotada
aqui no Brasil). A tabela inclui:
- 95 caracteres imprimíveis (incluindo o espaço)
- 33 códigos de controle (não imprimíveis)
---
class: nonum
A tabela ASCII é um dos
_encodings_
mais antigos ainda em uso na
atualidade. A forma original usa apenas 7 bits e tem, por isso,
apenas 128 caracteres e não incluia caracteres acentuados, por
exemplo. Hoje, embora se use Unicode, os primeiros 128 códigos
são idênticos à tabela ASCII.
Diversas extensões foram criadas, usando 8 bits, para ajustá-la
ao tamanho do byte e para aacomodar mais 128 caracteres. Uma das
mais usadas é a conhecida Latin-1 ou ISO 8859-1 (que era adotada
aqui no Brasil). A tabela inclui:
- 95 caracteres imprimíveis (incluindo o espaço)
- 33 códigos de controle (não imprimíveis)
---
class: nonum
 ---
# Unicode e UTF-8
---
# Unicode e UTF-8
 A necessidade de acomodar caracteres de outras linguagens levou à
criação de Unicode. Trata-se de um padrão que associa códigos a
caracteres de todos os idiomas conhecidos, emojis e códigos de
controle. Atualmente, inclui perto de 150.000 caracteres.
UTF-8 é uma forma de codificação (_encoding_) de tamanho variado
para representar caracteres Unicode (tanto pra armazenar, como
para transmitir). Embora existam outras formas de codificação,
UTF-8 é, provavelmente, a mais usada na atualidade.
---
# O arquivo
A primeira abstração acima dos bits e bytes da máquina é
proporcionada pelo Sistema Operacional (SO). É o conhecido
.green[arquivo].
Um arquivo é uma .blue[sequência de bytes de tamanho]
.blue[arbitrário, com nome único] no sistema.
Dois aspectos (bastante) importantes a ressaltar:
1. É o SO, não a máquina, que cria a _ilusão_ dos arquivos. É o
SO que interage com dispositivos e esconde as peculiaridades
de cada um (os famosos _drivers_) e oferece ao usuário uma
interface uniforme.
2. São as aplicações, não O SO, que definem _formatos de
arquivos_. São as aplicações (programas que executam na
máquina, acima do SO) que definem formatos e dão significado
aos dados nos arquivos.
---
# Arquivos de texto e binário
É importante diferenciarmos: .green[arquivos de]
.green[texto] de .blue[arquivos binários].
- .green[Arquivos de texto] são arquivos cujo conteúdo é composto
exclusivamente de .green[linhas] .green[de texto]. Linhas de
texto, por sua vez, são compostas por uma sequência de
.green[caracteres imprimíveis] terminadas por um marcador de fim
de linha (EOL, acrônimo de _end of line_).
- .blue[Arquivos binários] é o termo que usamos para caracterizar
todos os arquivos que não se encaixam na definição acima de
arquivo de texto. São chamados assim, porque não há convenção
sobre o conteúdo desses arquivos e sobre como interpretá-los.
Cabe exclusivamente a cada aplicação.
???
Arquivos de texto são a base de Unix. Programas, scripts e
configurações em Unix são _arquivos de texto_. Editores criam e
editam _arquivos de texto_.
---
# EOL (end of line)
Um detalhe menor que pode fazer alguma diferença em algumas
situações é como o EOL é definido em cada sistema.
- em sistemas baseados em Unix, o EOL é, tipicamente, o caractere de controle
`\n`, chamado de _newline_;
- em computadores Apple (Mac e cia), o EOL é o
caractere de controle `\r`, conhecido como _carriage return_;
- por fim, nos computadores Windows, o EOL é formado pelos dois
caracteres em sequência `\r\n`.
Um bom editor de texto é capaz de reconhecer os três estilos,
além de permitir transitar entre essas alternativas, facilmente.
---
# Demo
- todo arquivo é somente uma sequência de bytes
- arquivos de texto vs arquivos binários
- arquivos de texto
- uso de `ls`, `cat` e `xxd` para investigar arquivos
- conteúdo ASCII implica em 1 byte por caractere
- conteúdo ISO-8859-1 (Latin-1) idem
- conteúdo Unicode UTF-8 tem caracteres com múltiplos bytes
- criando arquivos com `printf`
- (usar `p1 é 👍`, byte por byte (vendo
---
# Python
- ints e floats
- bytes e strings
---
# Arquitetura de Von Neumann
.center[
A necessidade de acomodar caracteres de outras linguagens levou à
criação de Unicode. Trata-se de um padrão que associa códigos a
caracteres de todos os idiomas conhecidos, emojis e códigos de
controle. Atualmente, inclui perto de 150.000 caracteres.
UTF-8 é uma forma de codificação (_encoding_) de tamanho variado
para representar caracteres Unicode (tanto pra armazenar, como
para transmitir). Embora existam outras formas de codificação,
UTF-8 é, provavelmente, a mais usada na atualidade.
---
# O arquivo
A primeira abstração acima dos bits e bytes da máquina é
proporcionada pelo Sistema Operacional (SO). É o conhecido
.green[arquivo].
Um arquivo é uma .blue[sequência de bytes de tamanho]
.blue[arbitrário, com nome único] no sistema.
Dois aspectos (bastante) importantes a ressaltar:
1. É o SO, não a máquina, que cria a _ilusão_ dos arquivos. É o
SO que interage com dispositivos e esconde as peculiaridades
de cada um (os famosos _drivers_) e oferece ao usuário uma
interface uniforme.
2. São as aplicações, não O SO, que definem _formatos de
arquivos_. São as aplicações (programas que executam na
máquina, acima do SO) que definem formatos e dão significado
aos dados nos arquivos.
---
# Arquivos de texto e binário
É importante diferenciarmos: .green[arquivos de]
.green[texto] de .blue[arquivos binários].
- .green[Arquivos de texto] são arquivos cujo conteúdo é composto
exclusivamente de .green[linhas] .green[de texto]. Linhas de
texto, por sua vez, são compostas por uma sequência de
.green[caracteres imprimíveis] terminadas por um marcador de fim
de linha (EOL, acrônimo de _end of line_).
- .blue[Arquivos binários] é o termo que usamos para caracterizar
todos os arquivos que não se encaixam na definição acima de
arquivo de texto. São chamados assim, porque não há convenção
sobre o conteúdo desses arquivos e sobre como interpretá-los.
Cabe exclusivamente a cada aplicação.
???
Arquivos de texto são a base de Unix. Programas, scripts e
configurações em Unix são _arquivos de texto_. Editores criam e
editam _arquivos de texto_.
---
# EOL (end of line)
Um detalhe menor que pode fazer alguma diferença em algumas
situações é como o EOL é definido em cada sistema.
- em sistemas baseados em Unix, o EOL é, tipicamente, o caractere de controle
`\n`, chamado de _newline_;
- em computadores Apple (Mac e cia), o EOL é o
caractere de controle `\r`, conhecido como _carriage return_;
- por fim, nos computadores Windows, o EOL é formado pelos dois
caracteres em sequência `\r\n`.
Um bom editor de texto é capaz de reconhecer os três estilos,
além de permitir transitar entre essas alternativas, facilmente.
---
# Demo
- todo arquivo é somente uma sequência de bytes
- arquivos de texto vs arquivos binários
- arquivos de texto
- uso de `ls`, `cat` e `xxd` para investigar arquivos
- conteúdo ASCII implica em 1 byte por caractere
- conteúdo ISO-8859-1 (Latin-1) idem
- conteúdo Unicode UTF-8 tem caracteres com múltiplos bytes
- criando arquivos com `printf`
- (usar `p1 é 👍`, byte por byte (vendo
---
# Python
- ints e floats
- bytes e strings
---
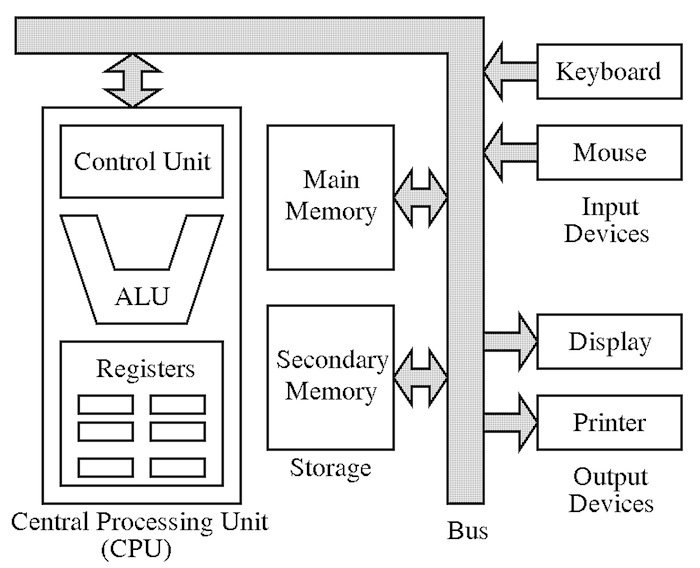
# Arquitetura de Von Neumann
.center[
 ]
???
]
???